Indic NLP Library
The goal of the Indic NLP Library is to build Python based libraries for common text processing and Natural Language Processing in Indian languages. Indian languages share a lot of similarity in terms of script, phonology, language syntax, etc. and this library is an attempt to provide a general solution to very commonly required toolsets for Indian language text.
The library provides the following functionalities:
- Text Normalization
- Script Information
- Tokenization
- Word Segmentation
- Script Conversion
- Romanization
- Indicization
- Transliteration
- Translation
Language Support
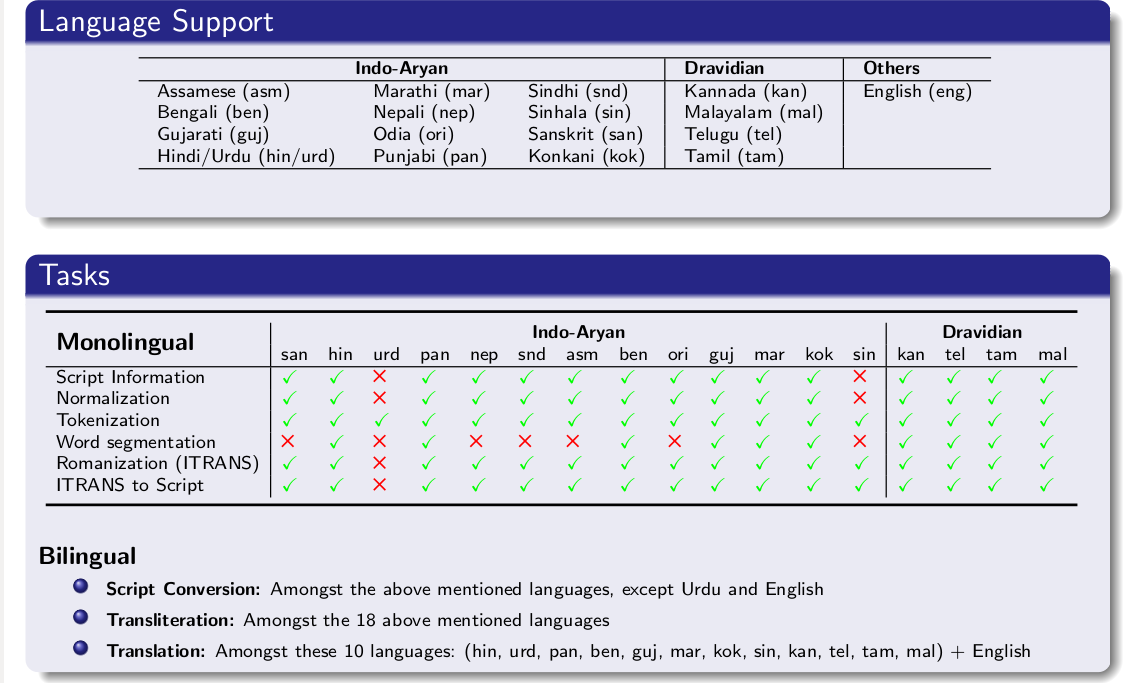
Pre-requisites
- Python 2.7+
- Indic NLP Resources: These resources are required by some modules
- Morfessor 2.0 Python Library
Download Examples
You can download this IPython Notebook to play with examples of the API usage. If you just to browse through the examples, read this on IPython NBViewer
Text Normalization
Text written in Indic scripts display a lot of quirky behaviour on account of varying input methods, multiple representations for the same character, etc. There is a need to canonicalize the representation of text so that NLP applications can handle the data in a consistent manner. The canonicalization primarily handles the following issues:
- Non-spacing characters like ZWJ/ZWNL
- Multiple representations of Nukta based characters
- Multiple representations of two part dependent vowel signs
- Typing inconsistencies: e.g. use of pipe (|) for poorna virama
You can check the documentation for each normalizer in the file
src/normalize/indic_normalize.py to know the script specific normalizations.
The following scripts are supported:
Devanagari(Hindi,Marathi,Sanskrit,Konkani,Nepali), Bengali, Oriya, Gujarati, Gurumukhi (Punjabi), Tamil, Telugu, Kannada, Malayalam
Commandline Usage
python src/indic_nlp/normalize/indic_normalize.py <infile> <outfile> <language> [<replace_nukta>]
<language>: 2-letter ISO 639-1 language code.
Codes for some language not covered in the standard
kK: Konkani
bD: Bodo
mP: Manipuri
<replace_nukta>: True/False. Default: False
API Usage
e.g.
from indicnlp.normalize.indic_normalize import IndicNormalizerFactory
input_text=u"\u0929 \u0928\u093c"
remove_nuktas=False
factory=IndicNormalizerFactory()
normalizer=factory.get_normalizer("hi",remove_nuktas)
print normalizer.normalize(input_text)
Unicode based Transliteration
Transliterate from one Indic script to another. This is a simple script which exploits the fact that Unicode points of various Indic scripts are at corresponding offsets from the base codepoint for that script. The following scripts are supported:
Devanagari(Hindi,Marathi,Sanskrit,Konkani,Nepali), Bengali, Oriya, Gujarati, Gurumukhi (Punjabi), Tamil, Telugu, Kannada, Malayalam
Commandline Usage
python src/indic_nlp/transliterate/unicode_transliterate.py <infile> <outfile> <language1> <language2>
<language1>,<language2>: 2-letter ISO 639-1 language code.
Codes for some language not covered in the standard
kK: Konkani
bD: Bodo
mP: Manipuri
API Usage
e.g.
from indicnlp.transliterate.unicode_transliterate import IndicNormalizerFactory
input_text=u"\u0929 \u0928\u093c"
print UnicodeIndicTransliterator.transliterate(input_text,"hi","pa")
Tokenization
A trivial tokenizer which just tokenizes on the punctuation boundaries. This also includes punctuations for the Indian language scripts (the purna virama and the deergha virama). It returns a list of tokens.
Commandline Usage
python src/indicnlp/tokenize/indic_tokenize.py <infile> <outfile> <language>
<language>: 2-letter ISO 639-1 language code.
Codes for some language not covered in the standard
kK: Konkani
bD: Bodo
mP: Manipuri
API Usage
e.g.
from indicnlp.tokenize import indic_tokenize
indic_string=u'\u0905\u0928\u0942\u092a,\u0905\u0928\u0942\u092a?\u0964 '
indic_tokenize.trivial_tokenize(indic_string)
Morphological Analysis
Unsupervised morphological analysers for various Indian language. Given a word, the analyzer returns the componenent morphemes. The analyzer can recognize inflectional and derivational morphemes.
The following languages are supported:
Hindi, Punjabi, Marathi, Konkani, Gujarati, Bengali, Kannada, Tamil, Telugu, Malayalam
Support for more languages will be added soon.
Commandline Usage
python src/indicnlp/morph/unsupervised_morph.py <infile> <outfile> <language> <resource_directory>
<language>: 2-letter ISO 639-1 language code.
Codes for some language not covered in the standard
kK: Konkani
bD: Bodo
mP: Manipuri
<resource_directory>: Path to directory containg Indic NLP library resources.
API Usage
e.g.
# -*- coding: utf-8 -*-
from indicnlp.morph import unsupervised_morph
from indicnlp import common
common.INDIC_RESOURCES_PATH="resources"
analyzer=unsupervised_morph.UnsupervisedMorphAnalyzer('mr')
indic_string=u'आपल्या हिरड्यांच्या आणि दातांच्यामध्ये जीवाणू असतात ."
analyzes_tokens=analyzer.morph_analyze_document(indic_string.split(' '))
Author
Anoop Kunchukuttan ( anoop.kunchukuttan@gmail.com )
Version: 0.2
Revision Log
0.3 : 21 Oct 2014: Supports morph-analysis between Indian languages
0.2 : 13 Jun 2014: Supports transliteration between Indian languages and tokenization of Indian languages
0.1 : 12 Mar 2014: Initial version. Supports text normalization.
LICENSE
Copyright Anoop Kunchukuttan 2013 - present
Indic NLP Library is free software: you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version.
Indic NLP Library is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with Indic NLP Library. If not, see http://www.gnu.org/licenses/.